Fine-tune Large Language Models the Easy Way: Complete Guide

If you’re looking to fine-tune large language models (LLMs) and get results fast, you’ve come to the right place. Entry Point is built as a layer on top of popular fine-tuning APIs to take care of all the technical details for you.
Here are just a few of the benefits of using the Entry Point platform for fine-tuning:
-
Token counts
-
Cost estimates
-
Easy CSV imports
-
Automatic JSONL formatting
-
Cross-platform LLM provider support (OpenAI, AI21, and more to come)
-
Search and manage training examples
-
Model validation
-
Synthetic training data generation
People say fine-tuning is “finicky” — that’s just because they don’t have the right tooling. Make fewer mistakes and get to quality outputs faster with Entry Point. You’ll be amazed at what you can do in minutes (not days)!
Let’s get started.
First, create an account at https://app.entrypointai.com
Set up OpenAI Integration
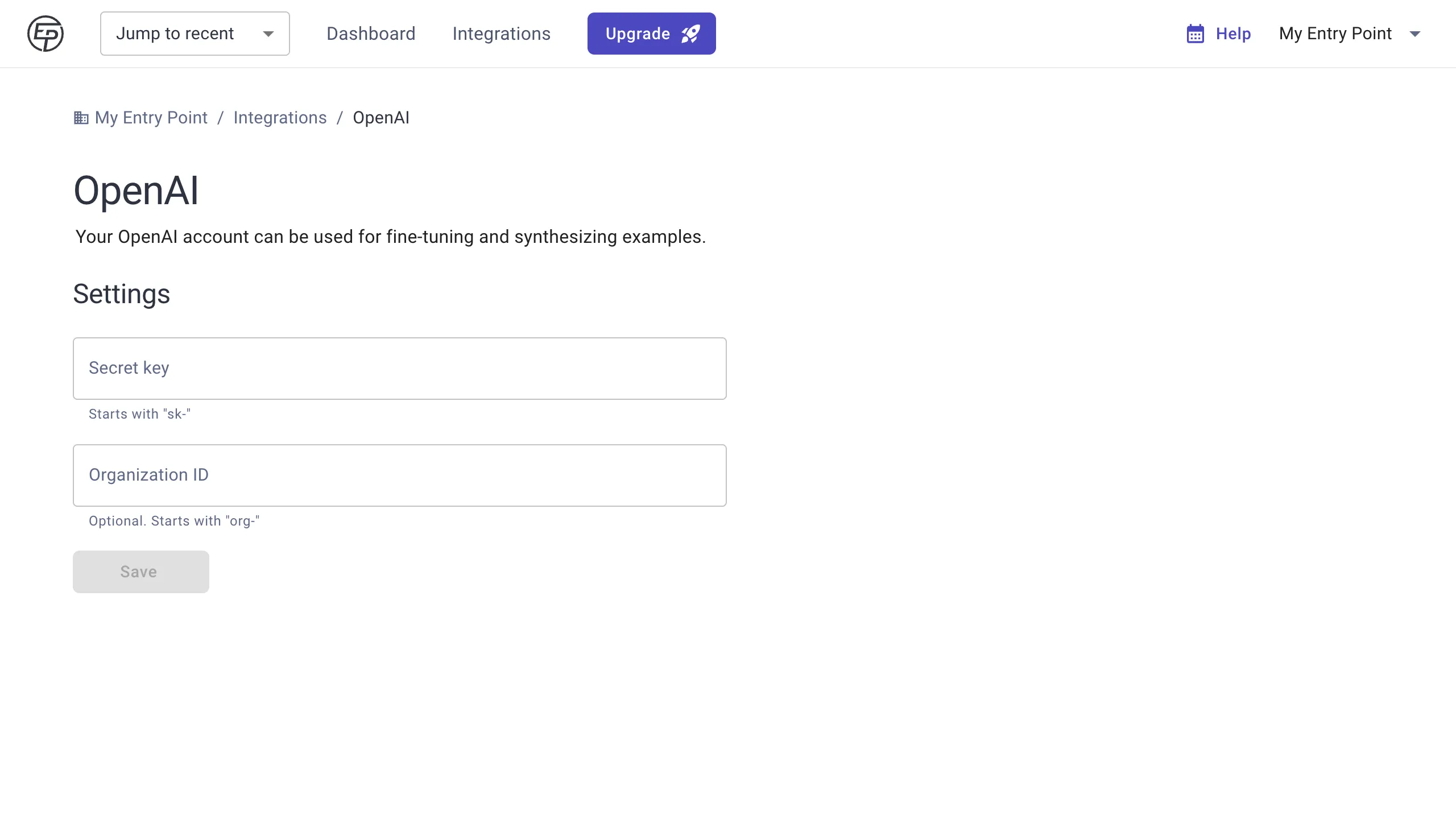
To set up your OpenAI Integration in Entry Point, click Integrations in the top nav.
Select OpenAI. Here you will see a form to enter your secret key.
In a separate tab, visit https://platform.openai.com/
Click your organization name in the top right, and go to View API Keys. Click “Create a new secret key.” Name it “Entry Point” and create.
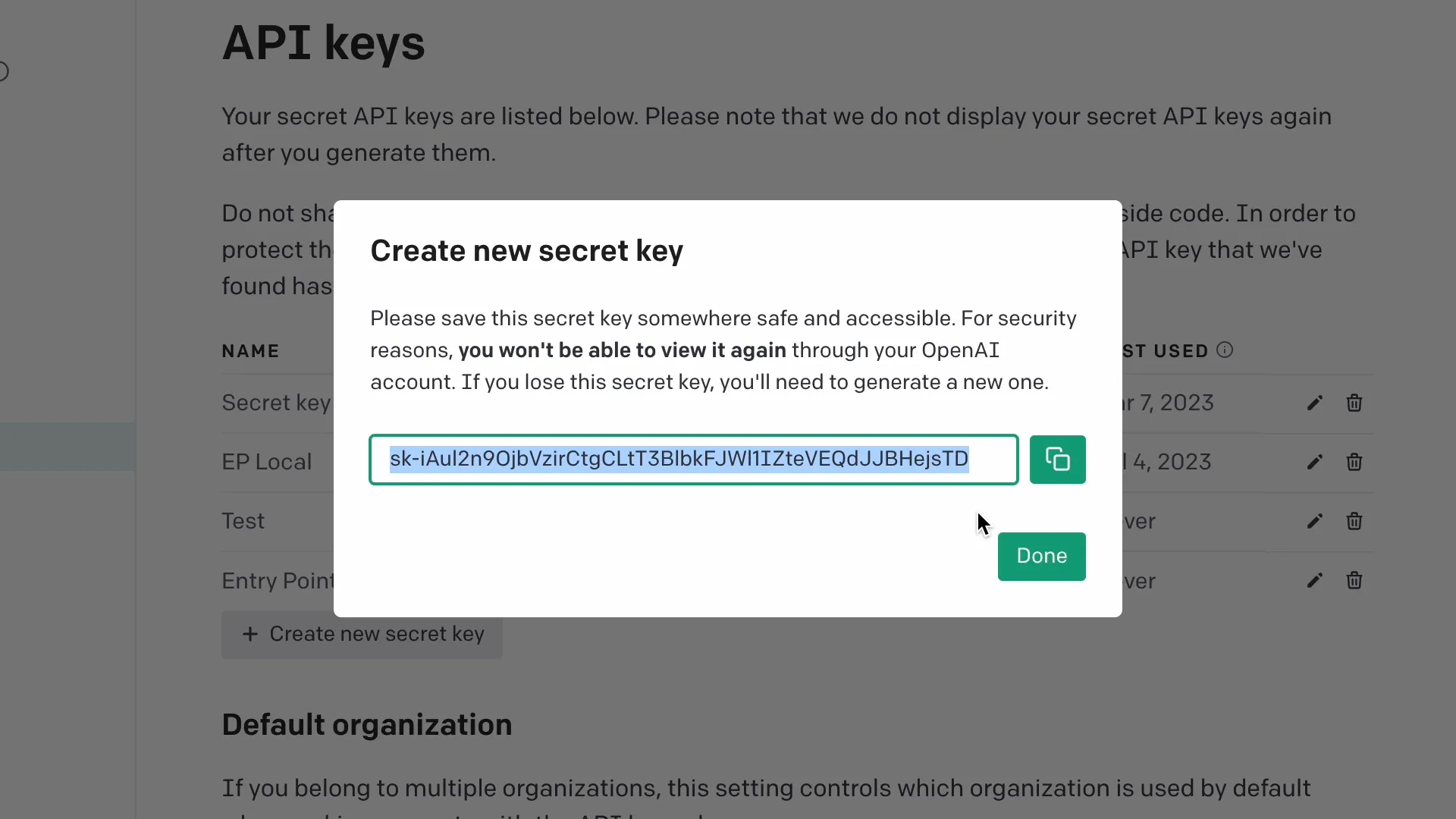
Click the “Copy to clipboard” icon and switch tabs back to Entry Point.
Paste your secret key into Entry Point and press Save.
Now you can use the Data Synthesis feature in Entry Point and fine-tune the LLMs available through OpenAI’s API.
You can optionally enter your organization ID if you have multiple organizations on OpenAI. This can be found on OpenAI under “Organization settings.”
If you don’t set the organization ID in Entry Point, all requests will use the default organization selected under API keys, which is fine for most users.
Create a Project
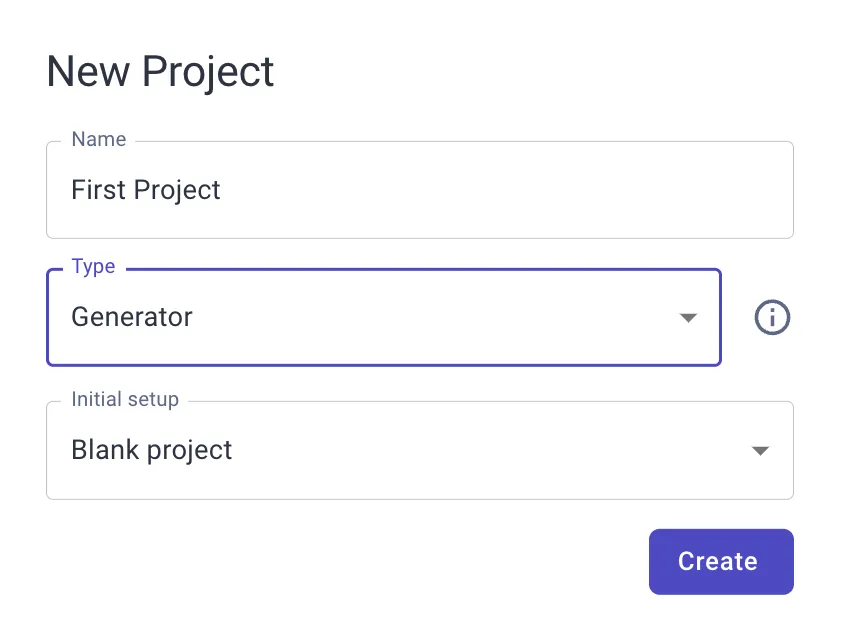
To create a project, open your Dashboard and click the add button.
Give it a useful name. For the type of project, choose either Generator or Classifier.
A Classifier is a special type of project that only outputs from a list of options. For example, if you want to classify the sentiment of a tweet as positive or negative, determine the genre from a movie description, or rank the priority of a support ticket.
Here are examples of possible outputs you might expect for a given type of classifier:
| Tweet sentiment classifier | Movie genre classifier | Support ticket prioritizer | Essay grader |
|---|---|---|---|
| positivenegative | actioncomedyfantasyromancethrillerhorrordocumentary | very highhighmediumlowvery lowspam | A+ABCDF |
If you plan to output multiple types of information or free-form content, choose Generator.
Here are some types of output you could expect from a Generator project:
-
Marketing copy (email subjects, email bodies, blog articles, social posts)
-
Code
-
JSON
-
Translations (e.g. from English to Spanish)
-
Chat responses (for support, sales, etc)
-
Analysis or reports on data
-
Multiple fields or classifications in one request (e.g. both the grade for a student’s paper and the reasoning or feedback for that grade)
For the initial project setup, you have the option to start with a simple prompt and completion. However, if you plan to import your data from a CSV, leave the project blank as Entry Point will help you create fields directly from your CSV columns.
Import Training Examples
Once you’ve created a blank project, you can import a CSV of training examples.
Press the Import button on the sidebar. Then, choose a .csv file.
Now, you can choose a field type for each of your columns. Entry Point will make its best guess for the defaults. Make sure to select at least one column for your model’s Completion, or output.
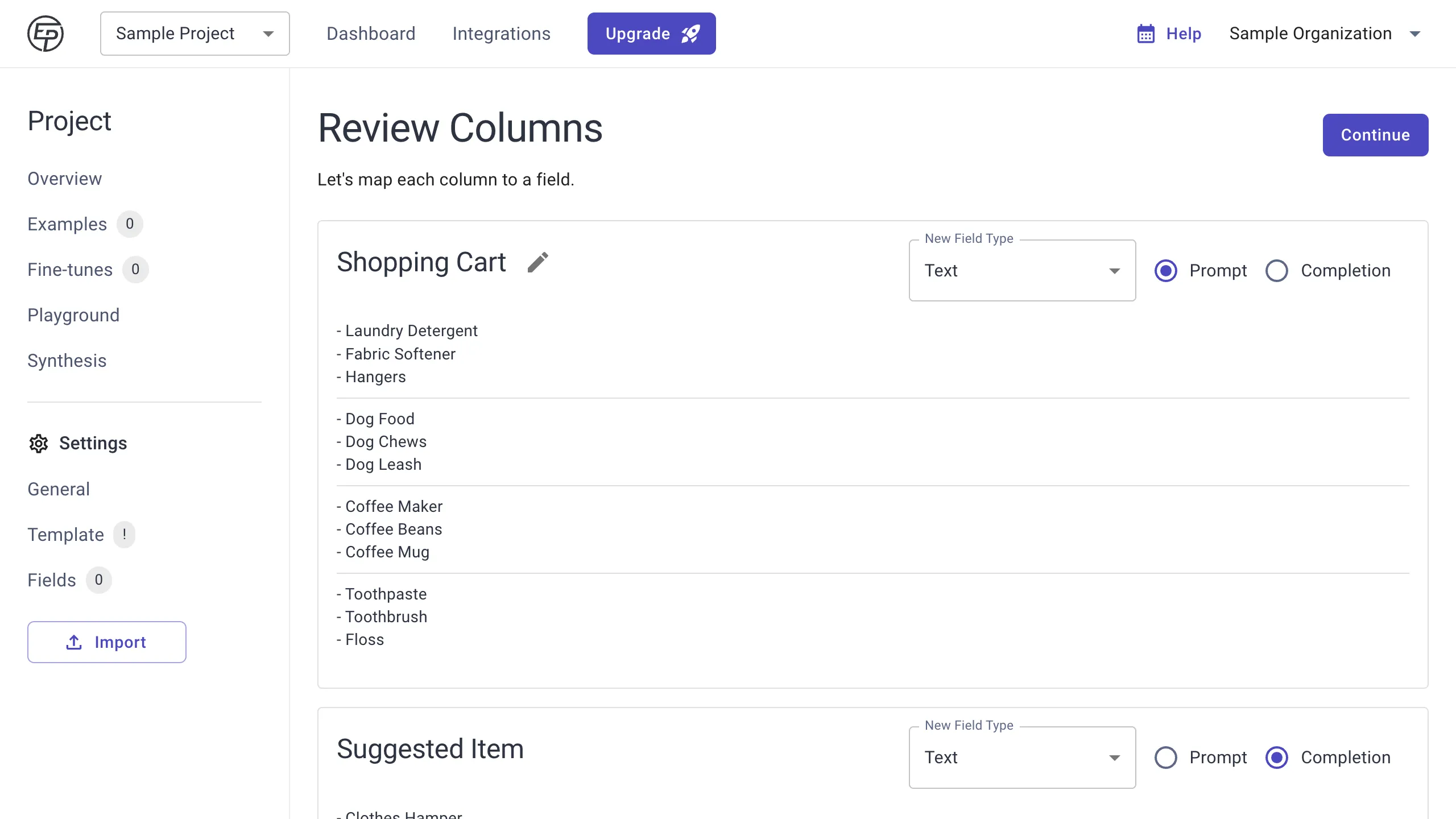
You can also hover over each column name to rename it.
For a Classifier project, only one field may be the completion, and it must be a Predefined Options field type, which is like a dropdown. Dropdown options will be created from the values in your CSV for this field.
When you’ve finished reviewing your field types, press Continue.
Finally, you can allocate a percentage of examples to validate the model’s performance after each fine-tune. You can leave this blank to use all your examples for training purposes and add validation examples later.
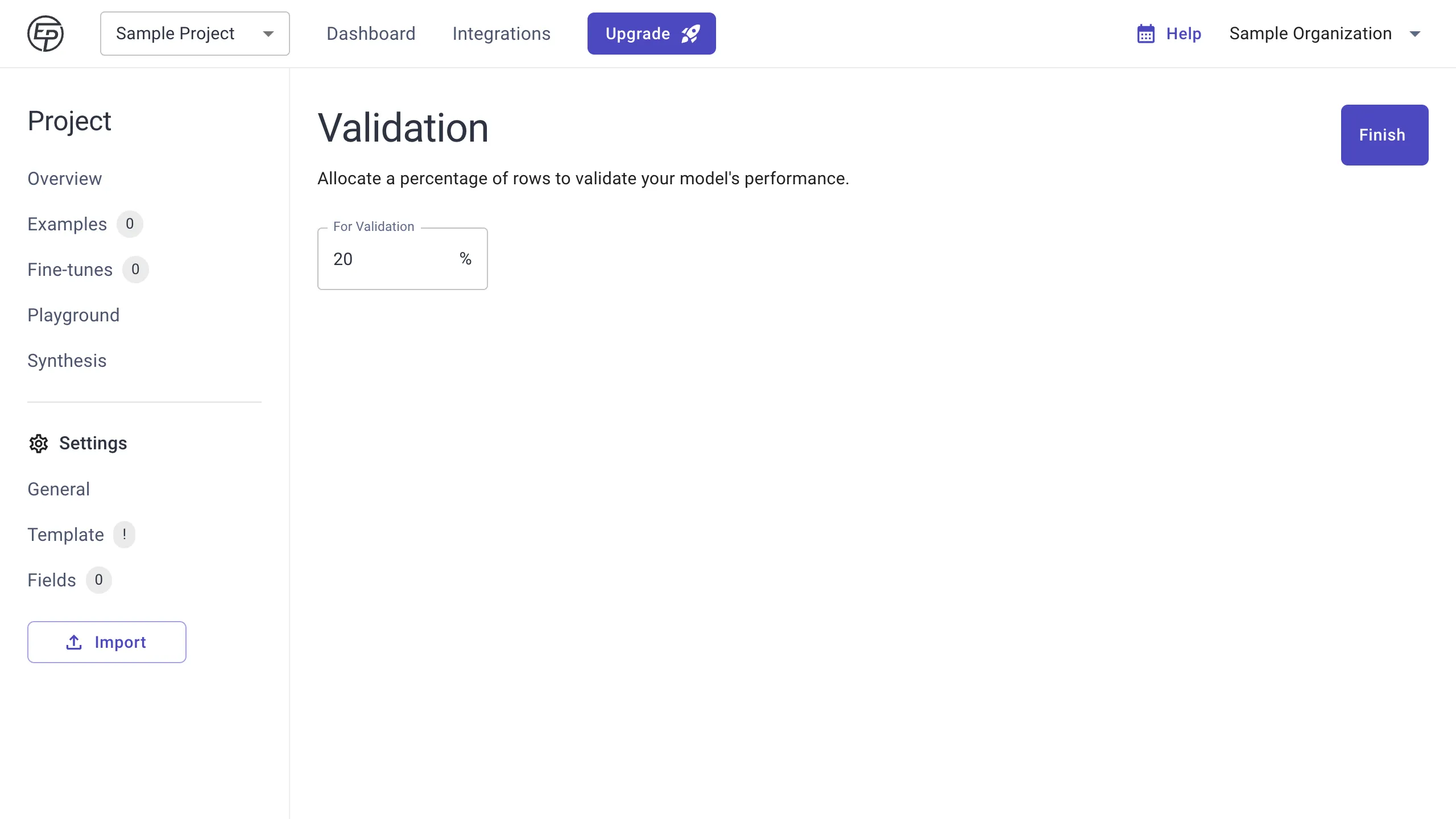
Press Finish, and your examples will be imported shortly.
Write Templates
After you’ve imported examples into Entry Point and created the fields, you can use references to those fields in your prompt and completion templates.
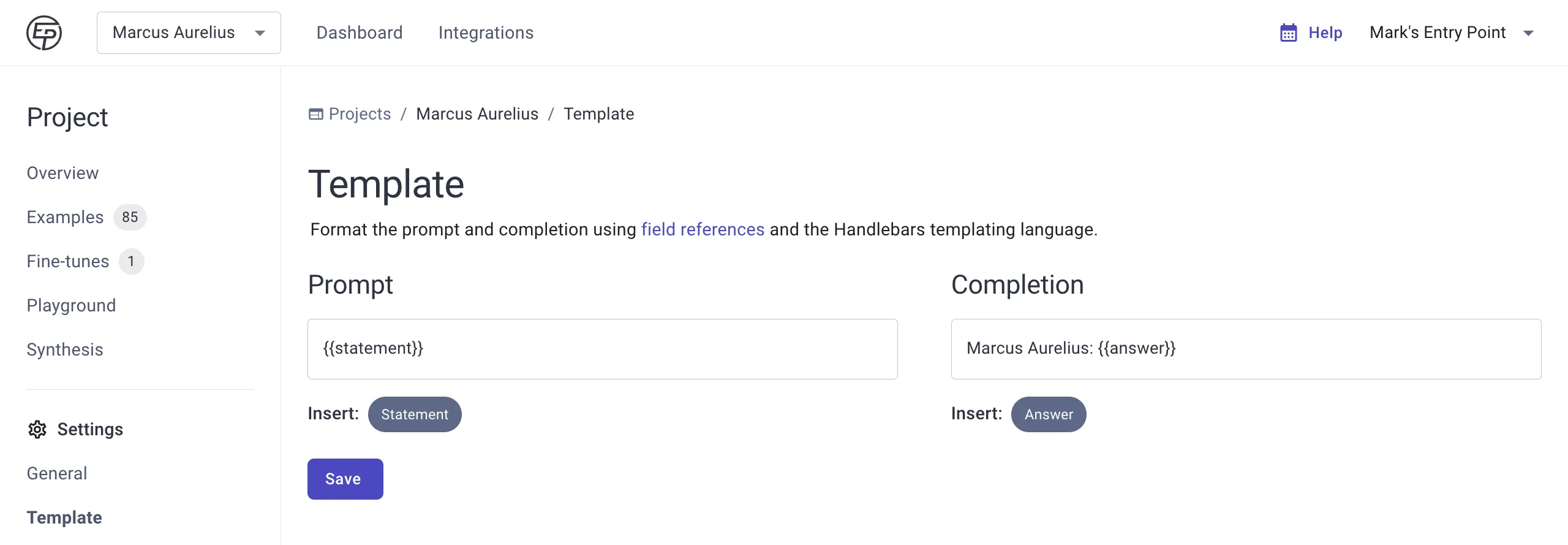
Templates are the text format that your examples follow. Distinguishing between the template and the field values in your examples allows you to keep your information separate, intact, and easily editable.
The template allows you to decide how your values are labeled and structured in the prompt and completion without having to edit the values directly.
When it’s time to fine-tune, Entry Point automatically generates the JSONL file with prompt/completion pairs by replacing your field references with your real example data for each example. That saves a lot of time and headaches over previous formatting techniques that involve the command line or writing Python scripts.
Prompt and completion templates in Entry Point use the common Handlebars templating language. Field references go in double brackets, like this: {{field_reference}}. You can type these manually or press the shortcut buttons to insert a field reference.
One benefit of the Handlebars templating language is that you can use its built-in helpers to provide a default value if the value of the field is empty.
It’s easy to find or edit your field references under the Fields tab. When you change a field reference, Entry Point will automatically update it in your template for you, too.
Best Practices for Fine-tuning Prompts
Keep in mind that writing a prompt template for a fine-tuned model requires a completely different approach than writing a prompt for ChatGPT.
In ChatGPT, you might write a prompt like this:
Write a blog article about the history of our solar system.
Whereas for a fine-tuned model, you would have a field called “Topic” with a prompt template that looks like this:
Topic: {{topic}}
Then, you would add examples of blog articles written for different topics, and the model would follow this pattern. If you wanted the output blog articles to have a certain style or follow certain writing standards, then you would ensure all your examples follow those same principles.
The fine-tuned model will learn the techniques by example, not from instructions in the prompt.
With enough examples, you can even remove the “Topic:” label from the prompt, and simplify it to just the data:
{{topic}}
With lower numbers of examples, semantic labels can help the model to understand the context of the data. As you increase your number of training examples, they become less and less relevant.
Add Enough Training Examples
You can always add more examples by importing another CSV with the same columns, or by adding them manually under Examples. Scroll down to the section called “Expand your Training Dataset” for more tips on how to add examples.
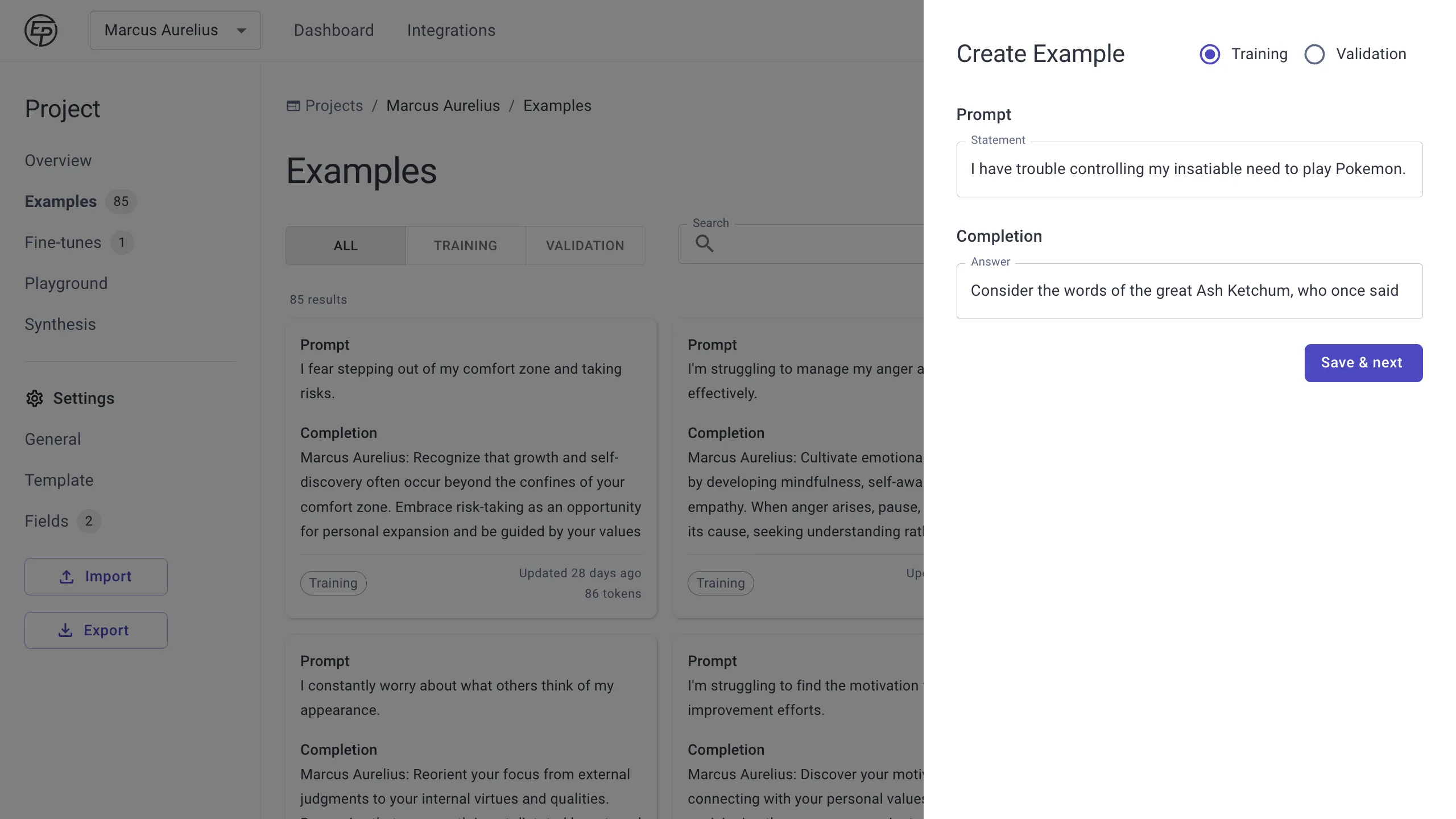
For a generator project, you should not attempt to run a fine-tune unless you have at least 10 training examples, and 25-50 will yield much better results. For a classifier project, aim for 5 per class at the minimum, or 10-20 per class for better results. These are rough numbers for you to get started and validate your fine-tuned model idea.
You will see significant improvements in your outputs as you get into the hundreds of training examples. With thousands of examples, you can continue to improve performance. You should not plan to use a model in production until you have hundreds of examples and have tested many possible edge cases in the playground.
Entry Point provides features like Data Synthesis and the Playground to help you add more examples, as well as tools to validate and compare the performance of models as you increase your number of examples.
Fine-tune a Large Language Model
Once your integration is set up, you have fields, prompt/completion templates, and enough training examples, you’re ready to run a fine-tune.
In your project, go to Fine-tunes, and press the add button.
Select the platform (OpenAI or AI21) for the integration you set up earlier.
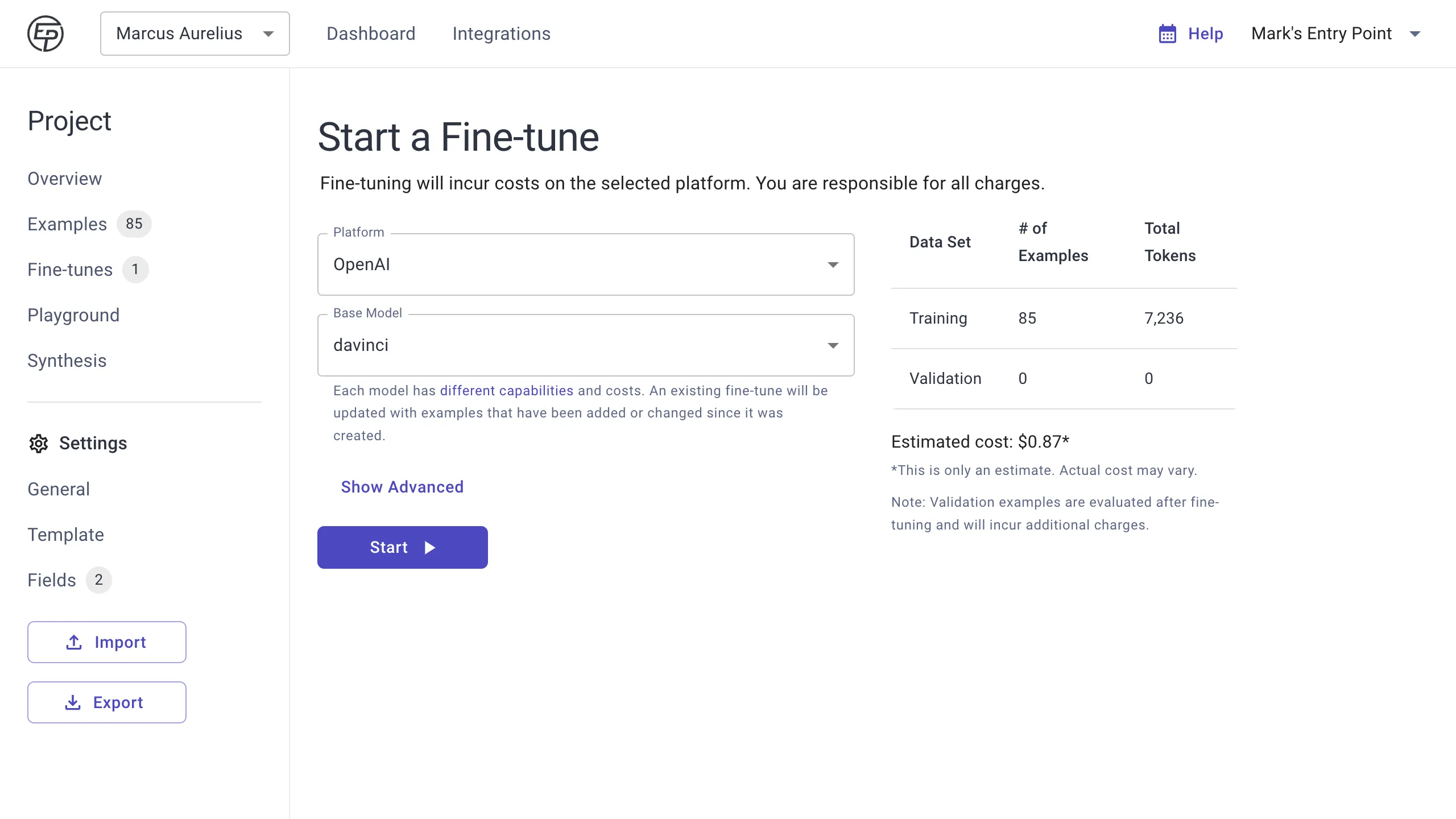
Choose a base model. Our recommended approach is to start with the most capable model (easy to identify as the most expensive one) to get a baseline performance, then and work your way down with additional fine-tunes on lesser models, seeing whether they can achieve acceptable results, or if you need to add more training examples to achieve those results on lesser models.
For complex writing tasks, you will want to stick to the higher end models.
| OpenAI Model | Recommended Minimum Number of Examples | Complex Writing Tasks | Classification |
| davinci | Dozens | ✅ | ✅ |
| curie | Hundreds | ❌ | ✅ |
| babbage | Thousands | ❌ | ✅ |
| ada | Thousands | ❌ | ✅ |
You can customize advanced fine-tuning hyper-parameters if you know what you’re doing. Otherwise, leave the defaults and press Start.
Fine-tuning a model often takes at least 20 minutes to over an hour.
Entry Point will send you an email when your model is ready.
Play with the Fine-tuned Model
You’re model is ready, congrats!
Entry Point has its own playground where you can easily test your fine-tuned large language model without making common mistakes like forgetting the separator or formatting the prompt incorrectly from your training data.
You can find the Playground in the project sidebar.
First, fill in values for your prompt fields. You can optionally use the OpenAI integration by pressing “Generate,” which will synthesize a prompt and completion using ChatGPT. Note that this does not involve using your fine-tune at all yet.
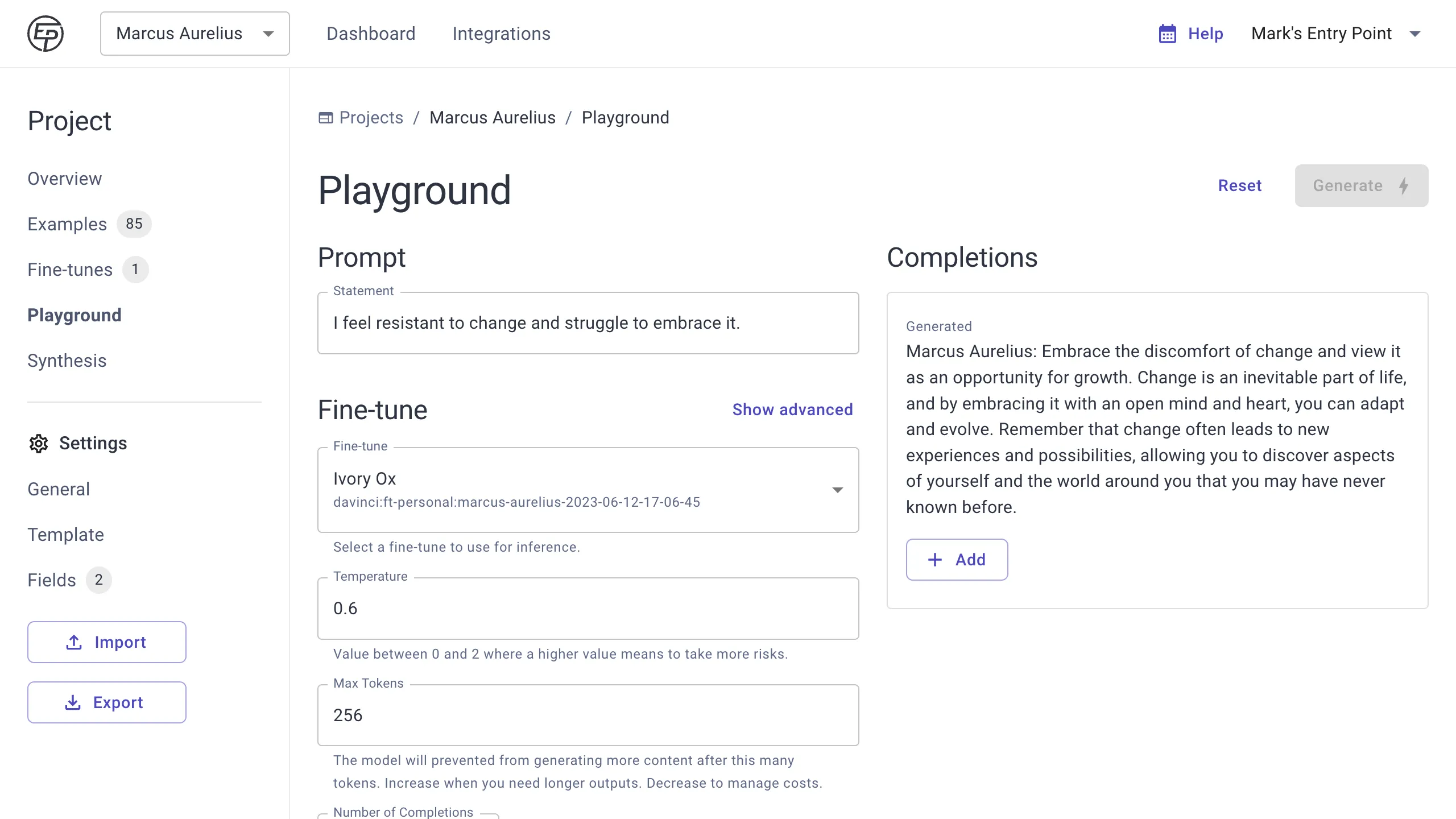
Then, select your fine-tune from the dropdown below. You can then use the prompt to test your fine-tuned model and generate one or more completions. Multiple completions are available when you set Temperature greater than 0 (when Temperature is 0, you get the same output every time, so there is no reason to generate multiple completions).
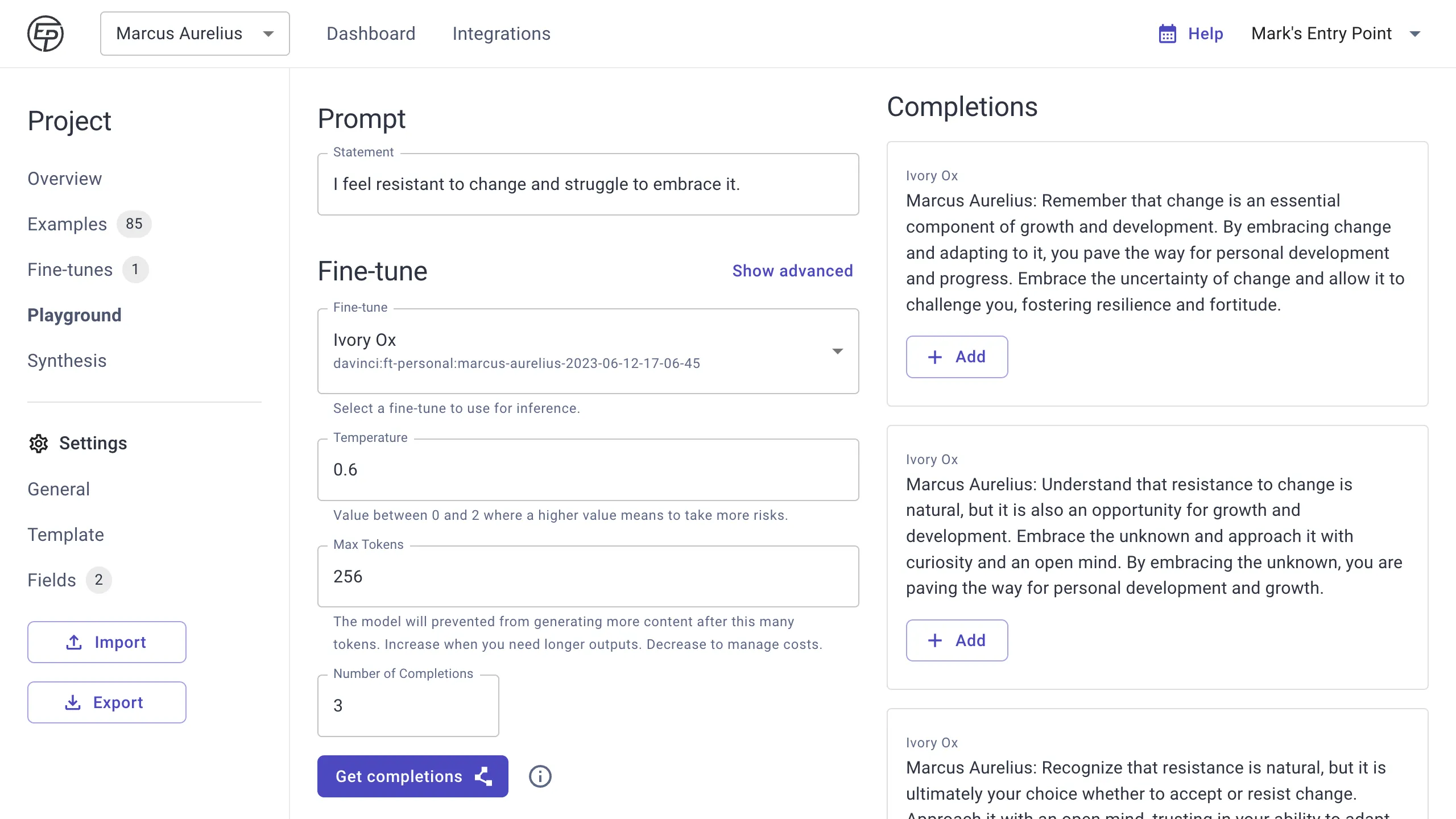
Temperature is an important parameter to understand, because it controls how risky or creative your model will get. Note that the higher the temperature, the more likely your model will do something completely unexpected, unrelated, or illogical.
We recommend starting with the default value, and testing up or down in increments of 0.1 to find a sweet spot for a Temperature that works well with your model and use case. In some cases, this may be 0 (especially for classifier type projects).
If your completions are getting cut off, try increasing the Max Tokens property.
Expand your Training Dataset
There are two convenient ways to expand your dataset in Entry Point, besides importing or writing them manually.
The first is by using one of your fine-tunes in the Playground, with a Temperature greater than 0 (try a range of 0.5-1.0), to generate three or more completions. Then review and select the best completion to save to your examples. Repeat this process with different prompts and grow your dataset.
The second is with our Data Synthesis feature.
Generate Synthetic Training Examples
Entry Point’s Data Synthesis feature makes it easy to generate more training examples for your fine-tuning dataset using ChatGPT.
Open Synthesis from the project sidebar.
First, click the Settings button to understand better how Synthesis works.
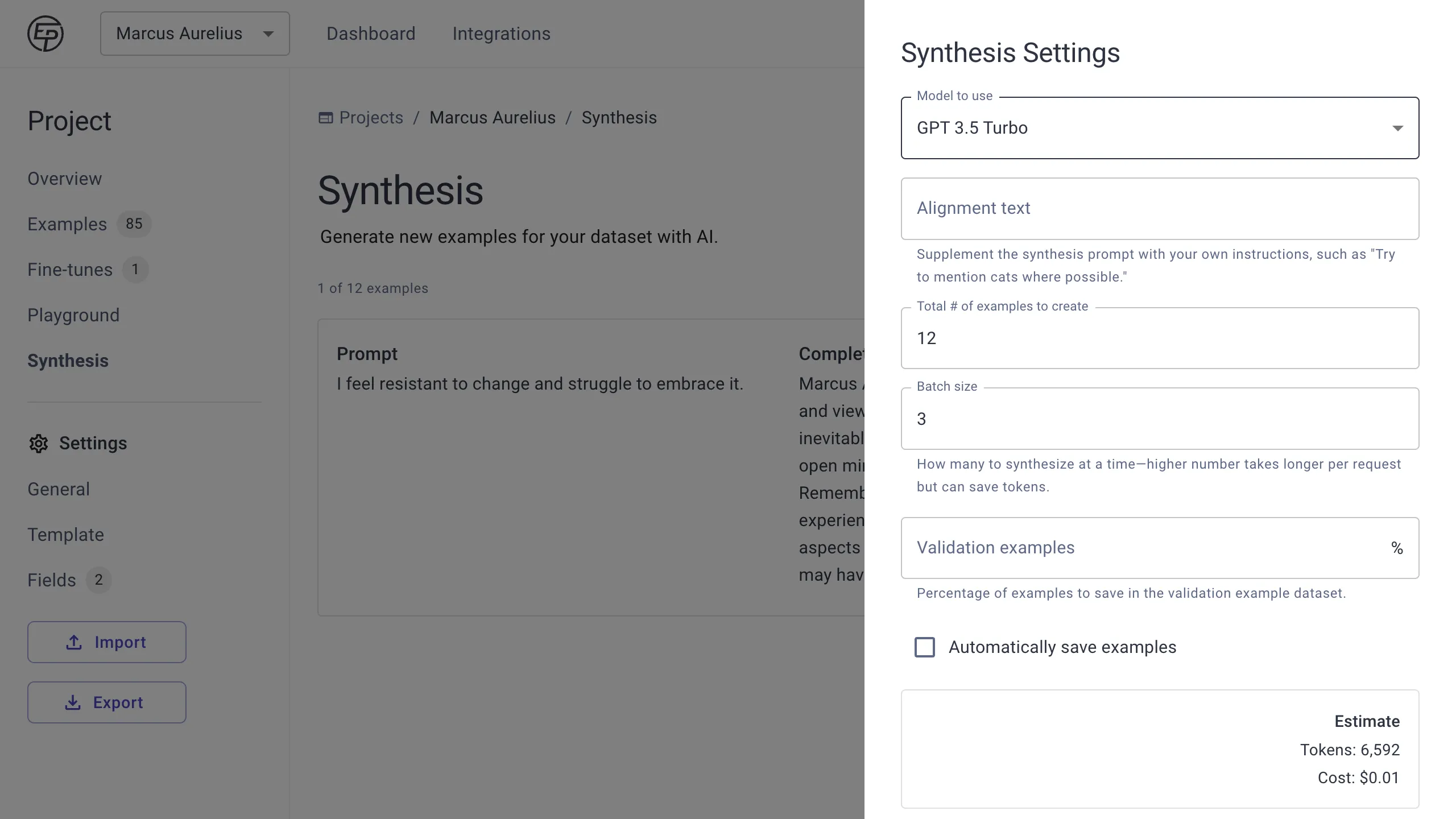
Entry Point generates examples in batches of a certain size, which you can adjust under Settings.
You can choose which OpenAI Chat model to use here. Selecting a model with a large enough context window is important, since Data Synthesis sends a randomly selected batch of your examples to ChatGPT, along with a prompt that includes the examples for few-shot learning. If your content window is too small, you will get an error message when you try to use Data Synthesis.
Longer batch sizes take more time but may help optimize token costs. If you are reviewing and adding synthesized examples in real-time, you can figure out a batch size that allows you to finish adding examples from one batch right around the time that the next batch is generated. The Total Number of Examples to Create will determine how long Entry Point keeps running batches to get to your total.
If you want to create examples that cover a certain edge case, use the Alignment Text field to inject your specific instructions into the prompt that generates the examples.
Finally, if you are confident that Data Synthesis is producing quality results, you can check “Automatically save examples.” Until then, you can generate examples, review them, and save them manually.
Make sure to save your settings, and then press Start to watch the magic happen.
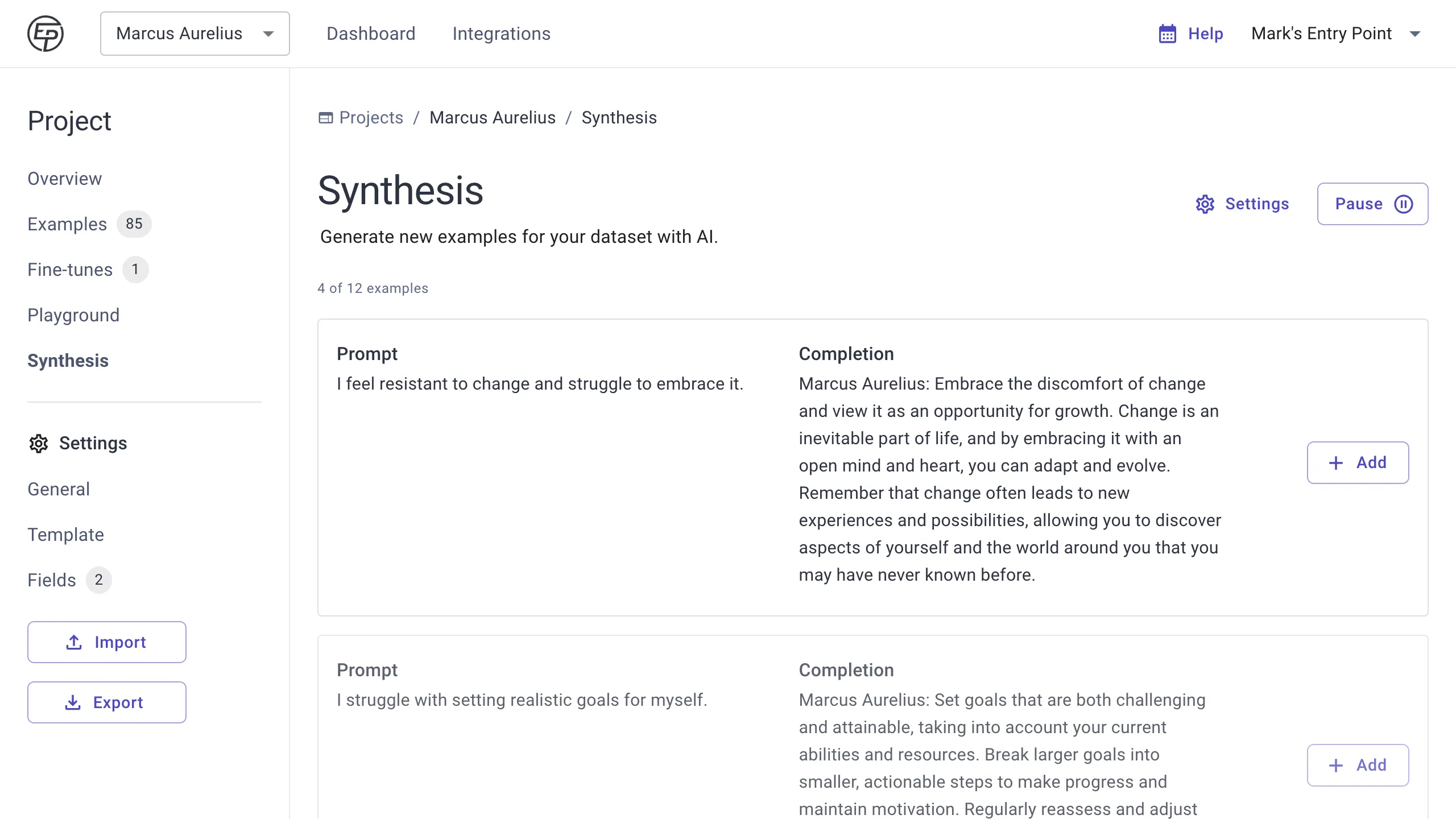
Users with the Labeler, Manager, or Admin role have access to the Synthesis feature. Consider inviting users who can add examples for you using this feature.
Next Steps
At Entry Point, we’re thrilled about the potential for fine-tuning LLMs, and we want to help you leverage them. After you’ve worked through this guide, please schedule a complimentary onboarding today and we’ll be sure to get you rolling on the super-AI highway.