Approaches to AI: When to Use Prompt Engineering, Embeddings, or Fine-tuning

As a product manager, startup founder, or prompt engineer looking to build AI features, there are numerous approaches to optimize results from a large language model that can be difficult to navigate. Each has their pros and cons and can be valuable to your organization when applied in the right way.
In this article, we will compare prompt engineering, embeddings (in particular, retrieval-augmented generation), and fine-tuning, show you when it makes sense to use each, and even opportunities to use them together.
The most common place to start is writing prompts for a LLM foundation model trained on human instructions and preferences, like ChatGPT or Claude.
Prompt Engineering
Prompt engineering is a term for writing and revising prompts to get the quality, structure, and consistency of outputs you need from a chat-based LLM.
Prompt engineering has a ton of benefits:
-
Quick and easy to get decent results that can be improved with few-shot learning
-
Allows a product team to bring new AI features to market very quickly. Writing prompts is intuitive and incredibly powerful, so the results can quickly impress users.
-
Great at general tasks like summarizing text, writing drafts, brainstorming ideas, and explaining concepts.
-
You don’t need to know any code. It’s all about how well you can write and test your results.
But it also has a lot of limitations::
-
Edge cases can be difficult to spot and solve without potentially compromising results in other areas.
-
Prompts tend to get long and this can run up against context windows (token limits).
-
Price increases fast with longer prompts.
-
Examples or instructions in a prompt may lose importance as the prompt length increases.
-
Completion format inconsistency can be hard to troubleshoot.
-
Generic models aren’t trained on certain types of specific information. While general LLMs have a vast amount of pre-training, which makes them excellent for many common use cases, they simply weren’t trained in-depth on many domains, including private, proprietary, or internal company information. Therefore, they have limitations in various domains.
-
LLMs can hallucinate information and this can’t be solved with prompt engineering alone.
-
Preventing prompt injection attacks from user-generated input can be difficult with prompt engineering alone.
Prompt engineering is the perfect choice to validate that a LLM can handle a task or solve a problem for an MVP. In many cases, when backed by proper evaluation suites, its results are even good enough to deploy a new feature to production.
However, the temptation for product managers is to stay in the prompt engineering space, but there are many benefits from exploring other approaches such as embeddings and fine-tuning.
Embeddings
Embeddings is a term referring to the semantic meaning of your text in a mathematical vector form, which can be readily searched and compared to each other for similarity. In multi-modal models, images and other content can be converted into vectors in the same space as text.
Every time you generate output from a LLM, your text is first converted into embeddings — these are how the model works with ideas and meaning. The model also outputs an embedding at the end which is converted into text for the final result.
Embeddings have many use cases. For example, since they are completely valid mathematical structures, vector embeddings can be added to or subtracted from one another for very interesting results.
One of the primary use cases for embeddings is is to measure the similarity or dissimilarity of two blocks of text. The similarity can be used as a proxy for relevance to a user inquiry.
Retrieval-augmented Generation (RAG)
Retrieval-augmented generation (RAG) is a knowledge retrieval technique that uses semantic search to find relevant information to include in the prompt.
Here is a quick overview of how RAG works:
Stage 1: Prepare the database
-
Start with a corpus of knowledge (a collection of web pages, PDFs, etc)
-
Split your text into chunks (choosing from various strategies)
-
Convert each block of text into a vector (embedding)
-
Store the vector along with the original text in a database
Stage 2: Retrieve information
-
Start with a user inquiry or a topic (sanitize, paraphrase, or simplify using a LLM). E.g. “How does RAG work?”
-
Use a vector search function to find the most semantically similar or related information from your database (these have relevance scores with them, which is the distance between the vectors)
-
Decide which of those related texts to include in the prompt (choosing from various strategies)
-
Pray to the RAG gods that you got the right information! 🙏
If you want to create a chatbot that can answer questions about internal processes for your employees, RAG is an essential tool. RAG would allow you to search your internal company documentation for content that is relevant to a question, and provide it in a prompt for context so that the LLM can write a useful and accurate output.
RAG is important for this use case because, first of all, foundation models would most likely not have been trained on your company’s internal information already. Second, even with pre-training, LLMs tend to hallucinate information. When the correct knowledge is provided directly in the prompt, however, the LLM can leverage its analytical abilities and a correct answer become much more likely.
RAG is a great tool for:
-
Question and answer agents where the answers are not common public knowledge
-
Retrieving relevant information to improve your prompts and quality of completions
-
Reducing the chance of hallucination, since the model can draw directly from the context you provide it
-
Providing real-time information dynamically in the prompt
Disadvantages of RAG include:
-
Retrieving bad context will result in a bad answer. If your system doesn’t select a relevant context upfront, the model will provide a poor response or be unable to answer the question effectively.
-
The way you segment your information in the database can have an outsize impact on the quality of answers. If you retrieve information that doesn’t have all the information required to answer a question, then your answer may be incomplete. If you have large blocks of information and trust the model to extract the relevant parts, this can run your application into other challenges like larger costs and slower response times.
It’s worth noting that RAG requires either prompt engineering and/or fine-tuning in order for the model to understand how to process the information. It’s more like an add-on than an independent solution. Now, let’s look at fine-tuning.
Fine-tuning
Fine-tuning is the process of training an existing LLM model on a set of additional prompt/completion pairs to adjust its weights and biases. It is also known as transfer learning in machine learning speak. Fine-tuning allows you to leverage all the pre-training of a model, and then to specialize it for your task.
Fine-tuning can be used for big and small use cases alike.
For example, ChatGPT was created by fine-tuning a base GPT model on human preferences, using a process called Reinforcement Learning with Human Feedback (RLHF). Since then, it has been further fine-tuned for safety, so that it will decline to respond to inquiries that are dangerous, unethical, or violate laws. Fine-tuning can be an iterative process, where one model is fine-tuned multiple times and for different reasons.
However, OpenAI also has an API for fine-tuning, and you can start seeing significant changes in completion outputs by fine-tuning a model with as few as 10-20 examples.
Fine-tuning is great for:
-
Changing the expected format of your prompt and completions, which can save significantly on tokens and speed up requests. For example, ChatGPT was fine-tuned to expect conversational inputs and provide conversational outputs, but you could fine-tune a model that expects conversational input and instead of returning conversational output, immediately classifies the content in the message as “spam” or “not spam.”
-
Taking the next step beyond few-shot learning. If you can get decent results by using a few examples in your prompt to ChatGPT of what kind of output to provide, you can get great results by fine-tuning a model with thousands of examples.
-
Processing a high volume of requests. Since the fine-tuned models are specialized for your task and typically require fewer tokens in the prompt, they can often work faster and more consistently than chat-based models.
-
Reducing the risk of prompt injection attacks, since you can provide examples of these in your dataset and the LLM will learn when to ignore or flag this kind of content. However, no method is completely foolproof. There will always be a level of risk, and security should be a multi-layered effort.
Fine-tuning is not a very good solution for:
- Teaching a model new domain knowledge. This is better accomplished with embeddings or by selecting a base model that already has the domain knowledge. While your examples do update the weights and biases, there is no guarantee recall of specific facts with fine-tuning.
In the future, there could be specialized base models available for fine-tuning, pre-trained for fields like law, finance, medicine, education, or software engineering. These models could have more or higher quality training data for their respective domain that makes them ideal candidates to fine-tune for a task that requires knowledge in that area. Being able to leverage models like this could lead to even better results than are produced by the general LLMs we have today.
Using the Approaches Together
Prompt engineering, fine-tuning, and RAG all have different strengths and weaknesses.
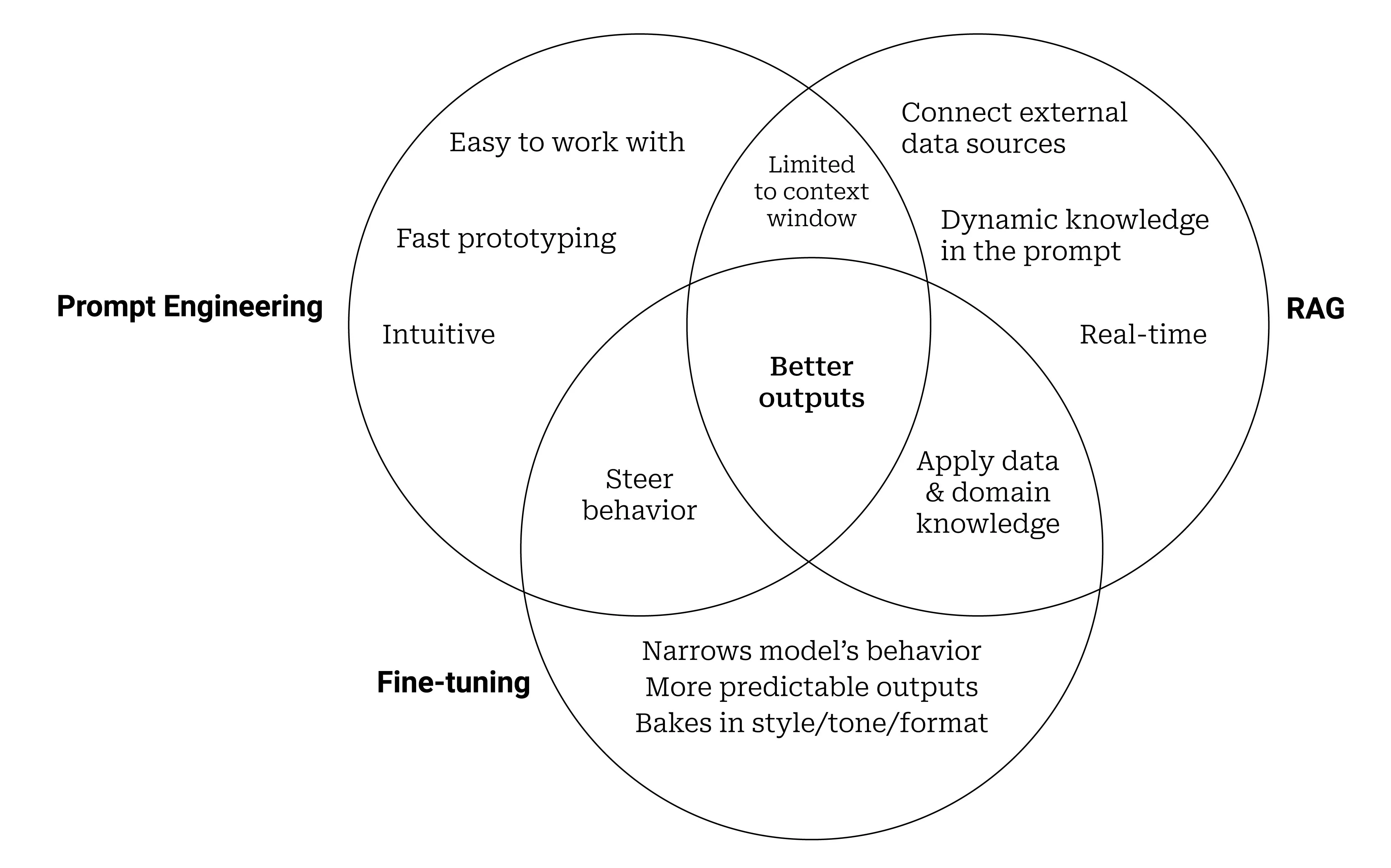
However, none of these techniques are mutually exclusive —they can be used together to get the best possible results from a LLM.
From Prompt Engineering to Fine-tuning
First, let’s see how fine-tuning can be an optimization to an engineered prompt.
Let’s say you’re a professor using ChatGPT to generate exam questions for your tests. You might start with a prompt like this:
You are a high-regarded professor in the legal profession who writes tough test questions. Generate a list of 30 final exam, multiple-choice questions on the topic of contract law. Provide 4 plausible answers (A, B, C, and D) to each where one and only one is correct. Mark the correct answer with “(correct)” after the answer.
Now after validating this works and using it for a while, you will have a history of good examples it produced. To optimize your process further, you can take these examples and fine-tune a model. Then you would simply need to pass a value for the topic to the model to get the same output:
Topic: Contract law
The output would follow the same format, but the model would learn how to do the formatting from the examples you provide, instead of explicit instructions in the prompt. Optionally, for fine-tuning on an instruct-tuned model, you could still include the prompt for additional reinforcement.
If the fine-tuned model was trained on the same model being used for the original prompt, it can even do a higher quality job, because it was trained on many real examples, whereas the base model had to guess based on instructions alone.
Fine-tuning allows you to impart more complex and subtle behavioral cues to the model that might be hard to clearly describe outright.
Using a Fine-tuned Model with RAG
Fine-tuning and RAG can be complementary. According to OpenAI:
By default OpenAI’s models are trained to be helpful generalist assistants. Fine-tuning can be used to make a model which is narrowly focused, and exhibits specific ingrained behavior patterns. Retrieval strategies can be used to make new information available to a model by providing it with relevant context before generating its response. Retrieval strategies are not an alternative to fine-tuning and can in fact be complementary to it.
Imagine that you have a chat-based prompt template that requires both a user-generated question and contextual content retrieved with embeddings:
You are an expert in the legal profession. Answer the following question from a law student using the provided context. If you do not know the answer, say “I do not know.”
Question: (Question from law student)
Context: (Excerpt retrieved using embeddings)
Using a fine-tuned model, you can train it on examples that strip out the initial explanation from the prompt. Your fine-tuning prompt template would simply become:
Question: (Question from law student)
Context: (Excerpt retrieved using embeddings)
Then you would provide a dataset following this template.
The labels “Question:” and “Context:” are even optional depending on how many examples you provide to the model. Your completions would represent the best possible answers given the provided information.
In this way, you are still using embeddings, but fine-tuning makes the model ready to handle your content without the use of words and phrases to prime and instruct it.
Engineered Prompts with Fine-tuned Models
The release of fine-tuning for GPT-3.5 Turbo has created even more opportunities to combine the disciplines of prompt engineering and fine-tuning into one unified hybrid approach.
This is because GPT-3.5 Turbo is a chat-based model that is trained on a conversational structure (using Chat Markup Language or ChatML) that includes a “system” message, which is designed to include instructions that steer the output. That makes transitioning from a prompt engineering only approach to a fine-tuned model more intuitive, because you can simply includes your existing prompt instructions in the system message.
According to OpenAI, you can get substantial improvements with 50-100 examples using this approach, putting a dataset for fine-tuning within reach of almost anyone.
Here is a helpful excerpt from their updated fine-tuning guide:
We generally recommend taking the set of instructions and prompts that you found worked best for the model prior to fine-tuning, and including them in every training example. This should let you reach the best and most general results, especially if you have relatively few (e.g. under a hundred) training examples.
Since OpenAI is the market leader and GPT-4 is expected to follow the same structure when it’s released for fine-tuning later in 2023, this approach could become the gold standard. That would mean fine-tuning is going to become, at it’s core, a way to scale the number of examples you can provide from few-shot learning in your prompts.
No-code Fine-tuning on Entry Point AI
In the long-run, fine-tuning is set to play a crucial role in AI-based products. Fortunately, learning to fine-tune LLMs has never been easier.
At Entry Point AI, we understand that working with data can be overwhelming. That’s why our platform offers a flexible field architecture for seamless data import and management. The stress of data formatting takes a backseat, leaving you to focus on elevating your AI applications.
Training models becomes an effortless task—all you need is to design your prompt and initiate training with a single click. No more wrestling with Python scripts or command lines.
Entry Point AI isn’t just a product. It’s an all-encompassing solution for managing data, evaluating model performance, estimating costs, and much more. Just like fine-tuning is a natural step in your AI application optimization, consider Entry Point AI as your next logical progression in the AI journey.
Discover how we’re reshaping the fine-tuning landscape and simplifying your path towards optimal AI performance.