What are Fine-tuning Hyperparameters and How to Set Them

When fine-tuning AI models, you’ll come across four so-called “hyperparameters.”
These are:
-
Number of Epochs
-
Prompt Loss Weight
-
Learning Rate Multiplier
-
Batch Size
Here’s how they appear in Entry Point:
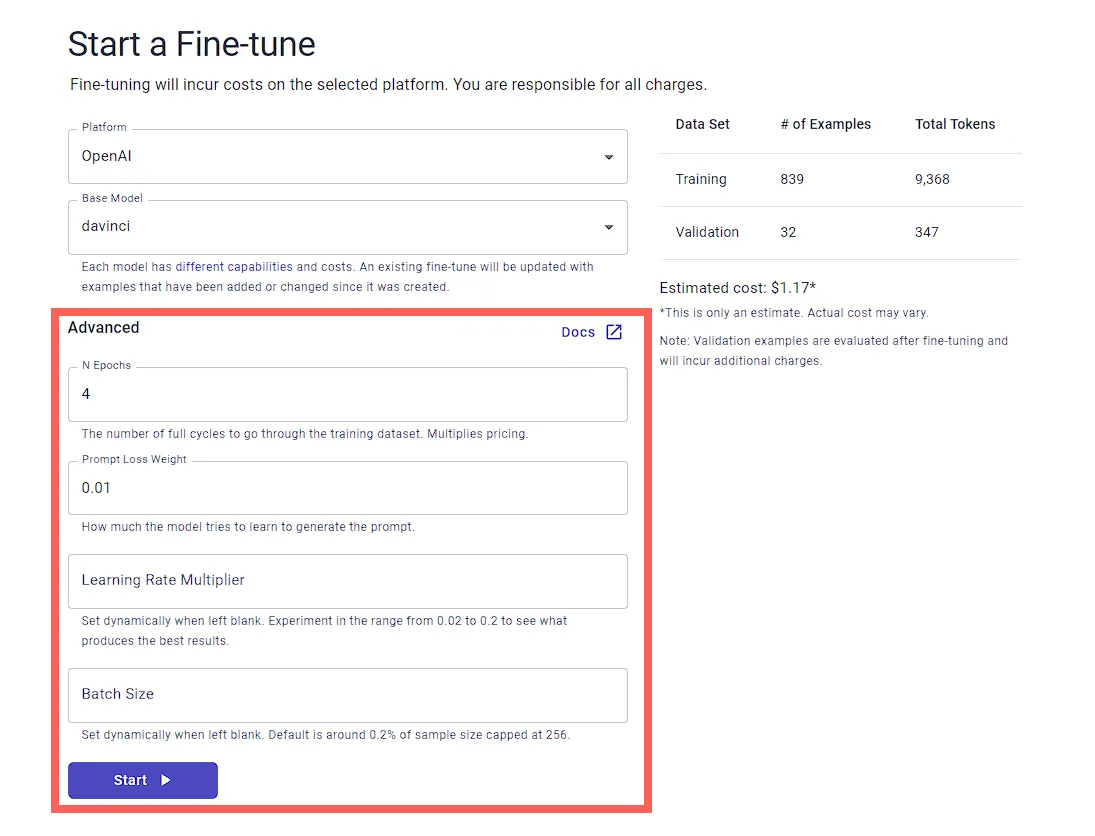
Hyperparameters are variables that you set before the training to control the learning process.
Think of a professor setting directions for how her course will go at the beginning of the school year. She might decide “we’ll go over these chapters four times because they’re important… I’ll give my students a semi-large homework two times a week not to overwhelm them… and I’ll make sure to let them know which topics they need to be particularly careful about before the final exam”.
How you set these will significantly influence your model’s performance and speed of learning. Unfortunately, there is no mathematical rule for setting them — the official method is trial and error.
(However, knowing exactly what each hyperparameter does can help you make better guesses!)
Let’s start with…
Number of Epochs
An “epoch” is a term used to describe one complete pass through the entire training dataset. In other words, if you have a training dataset of 10,000 examples, one epoch means that your model has had an opportunity to learn from each of those 10,000 examples once.
As you can imagine, changing the number of epochs has a significant impact on the performance of your fine-tuned model. But be careful!
1. If the number of epochs is too low: Your model might be underfitted, which means it could perform poorly because it hasn’t learned enough from the training data. In essence, it may not have had enough iterations to effectively learn and adjust its parameters (e.g., weights and biases).
2. If the number of epochs is too high: There’s a risk of overfitting, where the model becomes too specialized in the training data and performs poorly on unseen data (examples that weren’t in your training dataset).
With too many epochs, the model becomes too aggressive in seeking out patterns in your training data. It begins to see the “noise” as patterns that it should look out for, replacing its general knowledge as a large language model with this “overly-specialized knowledge”.
| State | Training Accuracy | Validation Accuracy | Test Accuracy | Description |
| Underfitting | 60% | 58% | 59% | The model is not learning well from the training data, resulting in low accuracy on both the training data and unseen data (validation and test data). It suggests that the model is too simple or the number of epochs is too low to capture the underlying patterns in the data. |
| Good fit | 90% | 88% | 90% | The model's performance on the training data is strong, and it also performs similarly on unseen data. This suggests that the model has learned the underlying patterns in the data effectively, without overfitting or underfitting. The number of epochs, model complexity, and other hyperparameters are set appropriately. |
| Overfitting | 98% | 75% | 74% | The model is performing exceptionally well on the training data but performs significantly worse on unseen data. This indicates that the model has become too specialized to the training data, and is not generalizing well to new data. |
Prompt Loss Weight
When fine-tuning a model, we often provide it with example pairs: an input (known as the ‘prompt’) and a desired output (often termed the ‘completion’). The goal? Train the model to produce outputs similar to our example completions when it encounters similar prompts.
This is important for two reasons:
-
Models “Think” Differently: Unlike humans, large language models don’t truly “respond” to prompts. Instead, they predict what comes next. Think of it like trying to guess the next word in a sentence. By fine-tuning, we’re guiding the model to “guess” in a way that gives a valuable or relevant response.
-
Completions Matter Most: We want our model to learn mostly from the completions we provide, not the prompts. This is where the Prompt Loss Weight comes in. It controls how much the model learns from the prompt.
The key is to try to find the right balance on what the model is learning:
High Prompt Loss Weight: This means the model pays a lot of attention to the prompts. It might even produce outputs that echo these prompts. This isn’t usually what we want.
Low Prompt Loss Weight: Here, the model doesn’t focus much on the prompts, making it learn predominantly from the completions. This is often the desired scenario. However, a weight of zero might be too extreme. Even a small value, like 0.01, can help stabilize the model’s learning.
The main takeaway? We typically want our model to focus more on the completions and less on the prompts. And remember, when adjusting the Prompt Loss Weight, it’s about fine-tuning its behavior, not feeding it facts.
Learning Rate
The Learning Rate lets you change different layers in a neural network at different speeds during training. Think of it like adjusting the knobs on different parts of the network, deciding which parts to change more or less as you go.
Imagine you’ve trained a large language model (LLM) to understand basic English, and now you want to make it understand slang. The basic English knowledge is like the early parts of the network, while the slang understanding is like the later parts.
Usually, the general knowledge, like basic English, doesn’t need many changes. The specific knowledge, like slang, might need more tweaks. This is where the Learning Rate Multiplier comes in handy.
If you pick a starting learning rate of 0.001, you can use the multiplier to tell the early parts (basic English) to change at a slower rate, maybe 0.0005. The later parts (slang) could change at a faster rate, like 0.002.
Picking the right multipliers can be tricky. You need to understand your model and what you want it to do. It’s about deciding how much of the old knowledge to keep and how much new knowledge to add.
When using a platform like OpenAI that offers a single Learning Rate Multiplier for an LLM, it means you’re adjusting all parts of the model at the same pace, much like turning up the volume for an entire orchestra instead of individual instruments. In our analogy, both basic English and slang would be tweaked at the same rate.
Instead of exposing the Learning Rate directly for fine-tuning, OpenAI provides a Learning Rate Multiplier hyperparameter that they use to multiply the original learning rate on the foundation model. By default, it’s set based on the Batch Size (discussed next).
According to the OpenAI documentation:
By default, the learning rate multiplier is the 0.05, 0.1, or 0.2 depending on final
batch_size(larger learning rates tend to perform better with larger batch sizes). We recommend experimenting with values in the range 0.02 to 0.2 to see what produces the best results.
To learn more about how neural networks work, watch this playlist by 3blue1brown.
Batch Size
“Batch Size” in machine learning means how many training examples you use at one time during training. Instead of training a model with all data at once (which can be too much for a computer to handle), we use smaller chunks or “batches”.
There are three main ways to use batches in training:
-
Batch Gradient Descent: Here, the batch size equals the whole dataset. The model checks every example, adds up their losses, and then tweaks the model. It does this for every round of training, called an epoch.
-
Stochastic Gradient Descent (SGD): This uses a batch size of just one. The model adjusts after seeing each single example.
-
Mini-Batch Gradient Descent: This is between the two above. The batch size is bigger than one but smaller than the whole dataset. This method is often used because it mixes the benefits of the other two. It’s quicker than Batch Gradient Descent and less noisy than SGD.
In real-world training, mini-batch is popular, and you get to choose the batch size. Common choices are 32, 64, 128, or 256, but the best size depends on your specific task and data.
Why does batch size matter? Well, a small batch size might make the training process jump around more but can speed things up and avoid getting stuck. A big batch size, however, can give a clearer direction for training, but it might be slow and need more computer power.
According to OpenAI documentation, this is how they select the default batch size for fine-tuning:
By default, the batch size will be dynamically configured to be ~0.2% of the number of examples in the training set, capped at 256 - in general, we’ve found that larger batch sizes tend to work better for larger datasets.
Conclusion
Most fine-tuning APIs provide sensible defaults for these that provide good starting points. Before testing a lot of different hyperparameters, make sure you tested different base models first, and also check for common mistakes when fine-tuning.